Heurist’s Guide to AI: Beginner’s Series Part 2
Welcome to our second blog article in the Beginner’s Guide to AI Series. Previously, our first article covered the concept of AI training and inference, and common types of AI models. Today let’s dive in the hardware that powers the AI revolution — GPU. Whether you’re new to AI or just looking to refresh your knowledge, this series of articles are for you.
A Graphics Processing Unit (GPU) is like a super-fast worker in computers. First, in gaming, it’s the magician behind stunning graphics, making your favorite games come to life with vibrant visuals. Then, in the crypto world, GPUs are typically used for POW mining such as Bitcoin and Ethereum Classic in which miners are rewarded for solving cryptographic puzzles. In the beginning of 21st century, General-Purpose computing on GPUs (GPGPU) came into existence. Think of it as a super-fast calculator that can tackle lots of numerical tasks in parallel. This makes it perfect for scientific research use cases such as simulations and experiments.
But why does AI specifically love GPUs? Well, GPUs are like super multitaskers. They can handle a large number of jobs at the same time, which is great for AI training and inference as there is a great amount of data that needs to be processed. The amount of numerical calculation is astronomical and takes unbearably long time if it’s carried out by a sequential processor like CPU, but GPU employs parallel processing that can handle hundreds of tasks all at once, thus speeding up the calculation significantly.
NVIDIA GPUs: The Leading Force in AI Compute
There are two major players in the GPU market: NVIDIA and AMD. But what makes NVIDIA GPUs the go-to choice for AI industry?
NVIDIA recognized the AI trend early and developed a comprehensive ecosystem with CUDA programming languages and software, giving it an edge in locking in customers. NVIDIA GPUs have been reported to outperform AMD’s in terms of speed and memory capabilities when it comes to AI tasks.
NVIDIA is expected to control a whopping 85% of the market for AI chips as of 2023. From aggressively ramping up the supply of AI chips to introducing new and more powerful chips, there are multiple reasons NVIDIA is likely to sustain its solid position in AI compute. More importantly, the company is now looking to boost its reach in other niches of the AI market as well, such as AI personal computers (PCs).

What are CUDA cores and Tensor Cores?
CUDA cores and Tensor Cores are specific components found in NVIDIA GPUs that play a crucial role in accelerating parallel processing and machine learning tasks.
CUDA cores are general-purpose processing units that handle a wide range of parallel tasks, such as rendering and mathematics-based workloads. Tensor Cores are specialized units tailored for the specific needs of deep learning workloads, offering improved performance for tasks involving matrix operations in neural networks.
The Tensor cores were first introduced in the Volta series of GPUs, such as the Tesla V100 and Titan V. Since 2018, Tensor cores have been added in RTX series GPUs that many gamers use (20, 30, 40 series), making them a great fit for both rendering and machine learning.
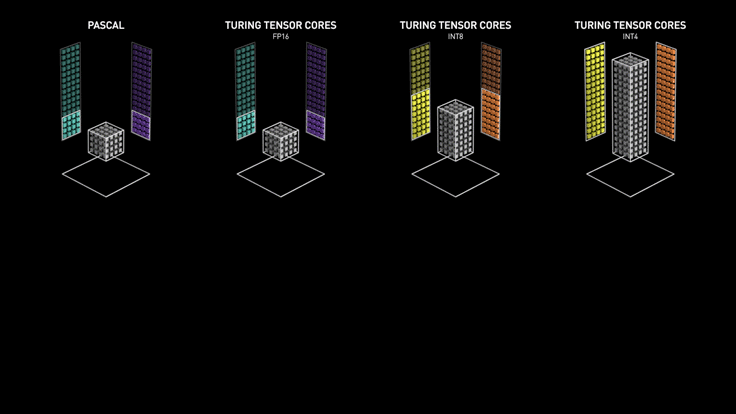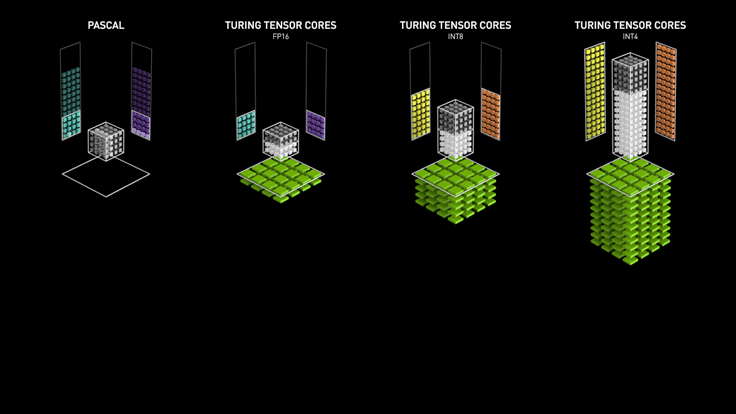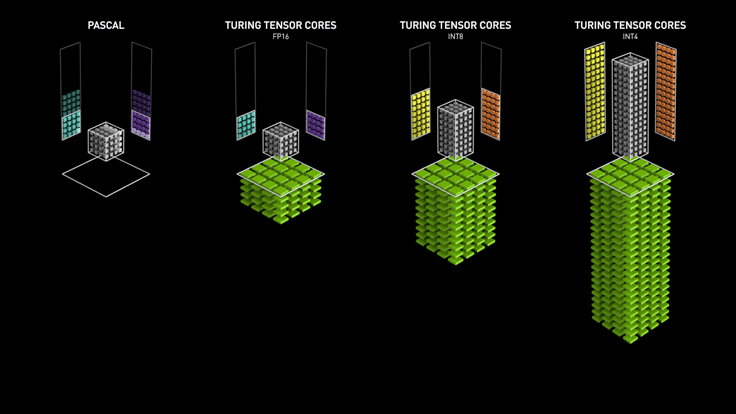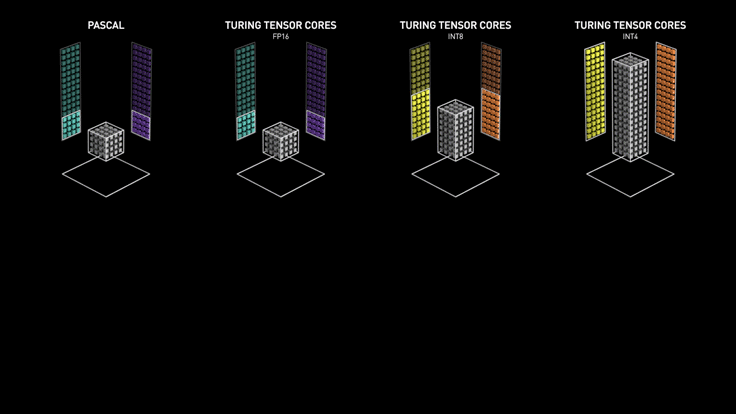
In summary, Tensor cores are much more efficient for deep learning and AI workloads involving large matrix operations. For smaller to medium-sized machine learning models, CUDA cores are sufficient to do the job. For larger models such as Stable Diffusion and Large Language Models (LLMs), GPUs equipped with Tensor Cores become a must.
Consumer GPU vs Datacenter GPU
NVIDIA’s consumer-grade GPUs, such as the GeForce and Titan series, are not intended for data center use due to their design, which is not optimized for the complex hardware, software, and thermal requirements of 24x7 operation in data center environments. As a result, NVIDIA updated the end-user license agreement (EULA) for its consumer GPUs to prohibit their deployment in data centers, with the exception of blockchain processing. This decision has led organizations to opt for the more expensive data center-oriented GPUs, such as the Tesla V100, which are designed to meet the demands of data center operations.
In contrast, NVIDIA’s data center GPU lineup, which includes products such as the DGX Systems, HGX A100, and vGPU solutions, is specifically built to accelerate high-performance computing, artificial intelligence, and machine learning workloads. These GPUs are designed to meet the rigorous demands of data center environments, making them more suitable for large-scale machine learning, as well as high-performance computing workloads.
However, it is not necessarily true that consumer-grade GPUs are not suitable for AI/ML workloads. As long as you are using RTX 20/30/40 series cards that have Tensor Cores, which is typically the case for most POW miners and gamers who purchased the hardware in recent years, you can also run Stable Diffusion or 7b LLM inference without any problems.
Naturally, very high-end datacenter cards like the A100 can handle orders of magnitude large models and datasets than the best off-the-shelf consumer GPUs, but the reality is that most people aren’t training gigantic LLMs from scratch.
Actually, Consumer-grade GPUs are a very cost-effective choice for AI inference tasks. For Stable Diffusion text-to-image inference, RTX 3090 which only costs $1500 out-performs datacenter-grade A6000 which costs $4800, and is only a little bit slower than the most popular A100 which costs over $10000.
The Importance of VRAM (Video Random Access Memory)
VRAM is special kind of memory that’s designed specifically for the tasks that GPUs handle, like gaming graphics or AI computations. VRAM capacity affects the size of models that can be loaded and the batch size that can be processed. For example, Stable Diffusion, a popular AI image generator, requires about 5–8 GB of VRAM to run, depending on the precision and batch size
For LLM, the VRAM usage varies based on the model size, precision, and the input and output text length. It takes more VRAM for LLM to process a long article that a single sentence. Having an adequate amount of VRAM is crucial for running these AI inference tasks efficiently and for handling larger models. Therefore, when choosing an NVIDIA GPU for AI inference, it is important to consider the VRAM capacity to ensure that it can support the specific requirements of the AI tasks.
We can reduce VRAM requirements by “quantizing” the model, making it more feasible to deploy large models on devices with limited memory. Quantization is a technique used to reduce the precision of numerical values in a model. It is like using shorter numbers to speed up the compute, but it comes with a trade-off between speed and accuracy. Finding the right balance is crucial to maintain both efficiency and precision. Typically, 16-bit float (half precision, fp16) is suitable for Stable Diffusion, and 8-bit integer (int8) or even lower precision is suitable for LLM without an obvious quality degradation.
GPU Recommendations for AI Inference
Want some specific guidance on buying GPU to create AI Art or chat with a locally deployed AI chatbot? We have some recommendations.
For Stable Diffusion Inference, we recommend using the following:
NVIDIA cards with at least 12GB of VRAM and with Tensor Cores (RTX 2060 and above)
For LLM, it’s more complex. We can use this website to estimate GPU memory requirement and inference speed for any LLM. We recommend using the following:
NVIDIA cards with at least 24GB of VRAM and with Tensor Cores (RTX 3090, 3090Ti or 4090)
The above are also the minimal requirements for running a Heurist miner node. We estimate that many gamers and home miners can host Stable Diffusion models on their existing devices without issues, but the 24GB VRAM requirement of LLM may frustrate community members who want to run LLM mining. Those highest-end consumer-grade GPUs are hard to be found on the market. Therefore, Heurist team is investing in purchasing our own 4090 clusters as well as partnering with GPU whales and datacenters to provide node rental service at a competitive price to our community. Stay tuned for more updates.
-
Our Twitter: https://twitter.com/heurist_ai
-
Discord: https://discord.gg/heuristai
-
Contact Email: [email protected]