A Tale of Two Points — Introducing Heurist Testnet Mining

We are excited to share the detailed plans for incentivized testnet mining starting from April 1st. The incentivized period will last until our Mainnet Launch. We focus on rewarding different GPU providers running different AI models in a fair and transparent way, bootstrapping the network compute capacity to provide reliable service to AI applications that are built on top of Heurist.
Problem Statement
Heurist Protocol allocates rewards to all miners at a fixed interval, with specific portions designated for different types of miners, such as those dedicated to Large Language Models (LLMs) and Stable Diffusion (SD) models. The hardware requirements and the demand of these two model categories are drastically different, therefore we must design the allocation rules differently.
The allocation is not arbitrary; it’s calculated based on the nature of AI models being used and the inference input/output parameters, as these determine the physical compute resources consumed and the time taken to complete an inference job. This article describes the testnet mining reward algorithm that is designed based on meticulous experiments and ensures that miner contributions are quantified fairly.

Introducing 🦙 Llama Points and 🧚♀️ Waifu Points
To infuse an element of fun into the testnet mining phase, we’ve devised a novel “point” system to quantify contributions. This system introduces two types of points:
- Llama Points, designated for LLM miners
- Waifu Points, designated for Stable Diffusion miners.
1 Llama Point equates to 1000 input/output tokens processed by Mixtral 8x7b model.
Note: This “token” is not cryptocurrency. In the context of LLMs, the term “token” refers to a chunk of text that the model reads or generates. A token is typically not a word; it could be a smaller unit, like a character or a part of a word, or a larger one like a whole phrase. Learn more about LLM tokens: https://docs.heurist.xyz/integration/heurist-llm-gateway#pricing
1 Waifu Point equates to the creation of one 512x512 image using the Stable Diffusion 1.5 model, completed over 20 iteration steps.
5% of Heurist Token supply will be airdropped to testnet miners at TGE. The token rewards will be fully liquid. The distribution ratio between Llama Points and Waifu Points will be determined when we come closer to TGE, taking into account the demand and utilization of the two model categories over the forthcoming months.
Next, let’s dive into our approach of calibration of this point system to make it applicable to any models and job input/output parameters.
Calibration of Points Through Benchmarking
We aim to answer this question: Given an arbitrary inference compute job, how many points should be rewarded to the miner?
Let’s consider SD and LLM separately. Benchmark scripts that we used are available at https://github.com/heurist-network/lambda-diffusers
Stable Diffusion
We used the NVIDIA RTX 2080Ti, 3090Ti and 4060Ti to run fp16 precision versions of Stable Diffusion 1.5 model. We then analyzed the relationship between image generation time and image resolution.
To quantify the relationship between the time and the number of pixels, we used an interpolation method to fit a formula. We can see from the chart that the time is approximately linear to the number of pixels, but not strictly linear.
The relative difficulty for processing an image of 1024x1024 pixels, compared to the baseline of 512x512 pixels, is:
- 4060 Ti: Approximately 5.85 times more difficult than processing a 512x512 pixels image
- 2080 Ti: Approximately 6.92 times more difficult
- 3090 Ti: Approximately 5.41 times more difficult
Even though a 1024x1024 image is 4x the size of a 512x512 image, the time it takes to generate a 1024x1024 image is 5~7 times of 512x512 size. The exact multiplier depends on the hardware type. We choose the middle point 6 as our calibrated multiplier regardless of GPU types, and we use linear interpolation based on the number of pixels to define the multiplier for other resolutions.
We also observed that the generation time is strictly linear to the number of iteration steps. Typically, a complete image takes 20 to 50 steps to generate. We don’t allocate any points to images generated with less than 20 steps to avoid spamming the network with low-quality images. Likewise, we don’t allocate any points to images that are less than 512x512 pixels.
As a result, let x be the number of pixels in the image, and y be the number of iteration steps. The Waifu Point for an image generated by Stable Diffusion 1.5 is given by the following formula:
Stable Diffusion XL (SDXL) is an upgrade to Stable Diffusion 1.5 (SD 1.5). SDXL is known for its ability to create higher-quality images at the cost of larger model size and longer compute time. Using similar benchmark methods, we have decided that the Waifu Point for an image generated by SDXL is 1.8x of SD 1.5.
LLM
For LLM inference jobs, the processing time for a given model is influenced by the length of input and output strings, measured by the number of tokens. Although there’s an asymmetry in the performance of handling inputs and outputs, our point system simplifies this by treating them equivalently. This approach is also adopted by the pricing models of many other commercial LLM API providers such as OpenRouter.
Let m be the number of input tokens and n be the number of output tokens. The Llama Point for a Mixtral 8x7b inference job is given by
To assign points to additional model types, we will adhere to a methodical approach akin to the ones above. This process begins with a calibration phase, where we select a specific GPU type as our benchmarking standard. We then conduct a series of experiments under various parameter combinations to measure the time it takes for this reference GPU to process tasks associated with the new model types. This empirical data allows us to understand the performance characteristics unique to each model and formulate a fair and equitable point allocation rule for each new model.
We also take the costs of GPU into account when designing the point allocation for LLMs, as larger models require significantly more GPU VRAM and those GPUs are much more expensive to buy/rent. Let’s jump to the conclusion without mumbling too much about the details.
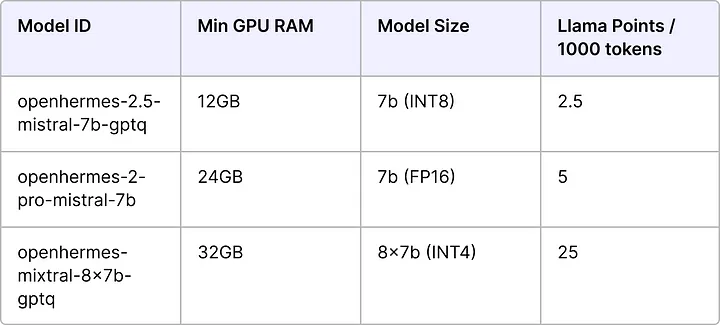
Hardware Requirements
Please refer to our previous article to learn more about the types of GPU and AI inference requirements. The following devices are recommended for the incentivized testnet.

Conclusion
In summary, our objective is to ensure that the points awarded accurately reflect the actual computational effort expended. As the Heurist network grows and integrates additional models, we will continue to evaluate the point allocation for new models based on a comparative model of existing benchmark results. This approach guarantees that the system for mining rewards progresses concurrently, maintaining fairness and the alignment of incentives.